
Anyone who has followed their LinkedIn or social media feed recently will almost certainly have encountered posts declaring data quality as the decisive success factor for AI. Typically accompanied by graphics and, more often than not, an implicit call to tidy up the data first before thinking seriously about deploying AI.
None of this is fundamentally wrong. But neither does it reflect the reality of every organisation.
Yes, “data quality matters” is a valid statement, but it leaves an open question: what, specifically, should be done about it?
A note on what follows: this article contains no emojis and no FOMO. Instead, it offers a source-based assessment and a different perspective on what “data quality” actually means for SMEs and family businesses in the context of AI.
TL;DR:
Data quality is not an isolated data problem. It is the result of organisational maturity. Organisations that launch a “data quality project” without first identifying use cases, defining processes, and documenting knowledge are investing in a façade without a foundation. Data quality does not improve through clean-up campaigns. It improves as an emergent outcome of a dynamic maturation process that is never truly complete.
Beyond FOMO – what does the evidence actually say, and where are the blind spots?
The good news is that the available research on data quality and AI allows for robust conclusions.
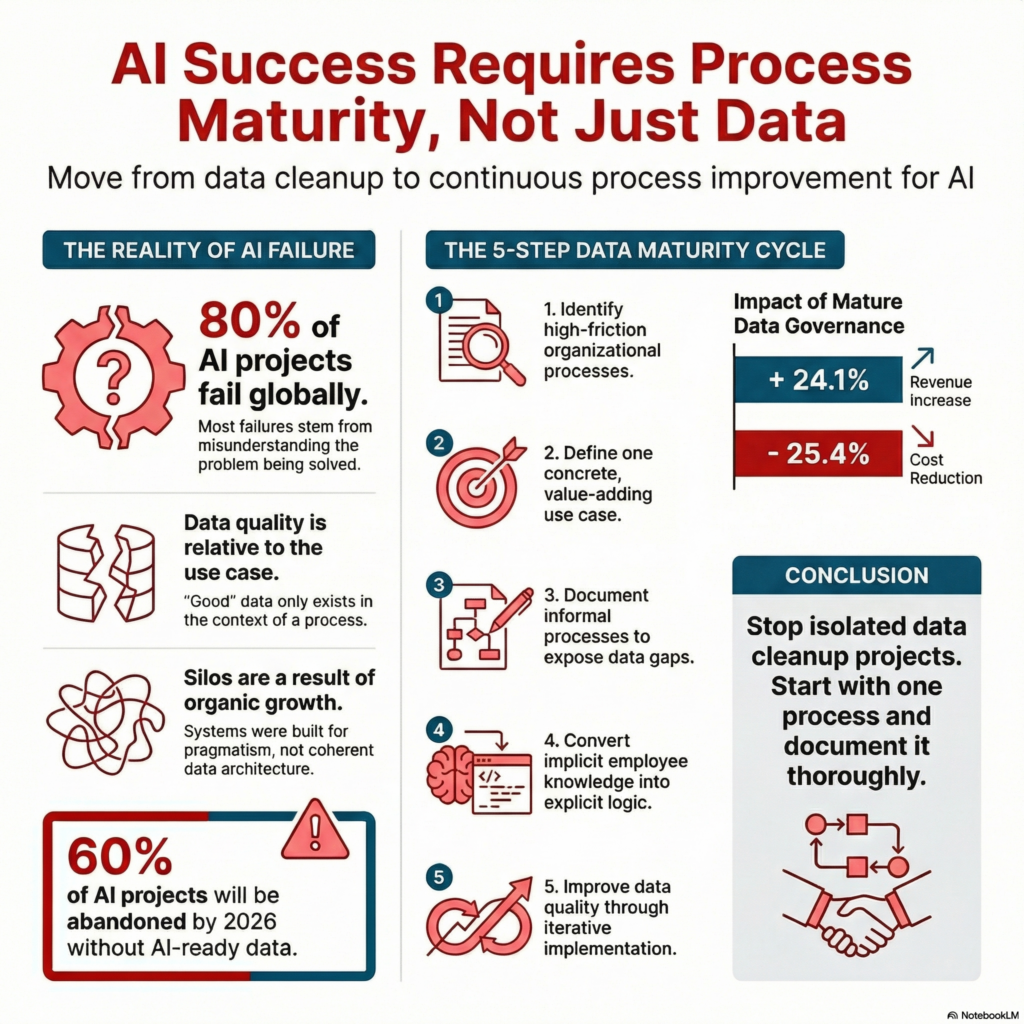
Gartner forecast that 60 per cent of all AI projects lacking AI-ready data would be abandoned by 2026 [1]. The underlying survey of 248 data management leaders was conducted as early as 2024. At that point, 63 per cent of organisations either lacked the appropriate data management practices for AI or were uncertain whether they had them [1].
For context: since 2024, the capability profile of AI systems, and with it the capacity for information extraction, has advanced considerably. What has not changed, however, is that data must be available and accessible before AI can process it. Better AI models shift the requirements for data – they do not replace them.
At the Gartner Data & Analytics Summit 2026, the original forecast was confirmed and sharpened: at least half of all GenAI projects had reportedly been discontinued after proof of concept.
For context: this was not solely attributable to data quality. Unclear value contribution and escalating costs were equally significant factors [2].
The Precisely/Drexel University study of January 2026 – a survey of more than 500 senior data and analytics leaders across the US and EMEA – reveals a striking discrepancy: 88 per cent of leaders report that their data is AI-ready. At the same time, 43 per cent of those surveyed cite data readiness as the greatest obstacle to aligning AI with business objectives [3].
For context: what initially appears contradictory is, in fact, a symptom. Precisely has termed it the “Agentic AI Data Integrity Gap.” It describes a situation in which organisations believe themselves to be well-prepared because they possess a broadly adequate infrastructure. However, the existence of infrastructure should not be confused with the ability to deploy that infrastructure effectively in the context of specific AI use cases [3].
The BARC Trend Monitor 2026 – with 1,579 respondents, one of the most comprehensive surveys in this field – offers a key insight: the most advanced organisations treat data quality as a shared responsibility rather than an IT function [4]. The Dataversity Trends in Data Management survey of 2025 confirms a similar pattern: despite growing awareness, only 15 per cent of respondents report mature data governance. Meanwhile, 61 per cent cite data quality as their greatest challenge [5].
For context: these findings carry real weight. The importance of data governance cannot be overstated. Yet, viewed collectively, the research may contain a blind spot: data quality is framed as a problem to be solved. And for problems, solutions tend to follow. The question that receives less attention is “why” – why data quality in so many organisations is the way it is.
What do we actually mean when we talk about “data quality”?
Before exploring that question, it is worth taking one step back. In current discussions, “data quality” is often treated as an absolute state: it is either good or bad. In practice, the picture is far more nuanced.
The classical dimensions of data quality – completeness, consistency, timeliness, accessibility – provide a useful framework. But they only become meaningful once an organisation knows what the data is actually needed for. Data quality is not an absolute state. It is always relative to the use case.
An example: if AI is deployed in marketing to analyse customer segments, then the relevant data must be available, current, and consistent for precisely that purpose. Data from production planning is irrelevant. “Good data” sitting in a silo may be perfectly adequate for a local use case. Conversely, data that has been consolidated enterprise-wide into a single system is of limited value if it cannot support the specific use case because it is incomplete or outdated.
What does this mean in practice? Organisations that frame “improve data quality” as an abstract goal without identifying the concrete use cases will struggle to define what “good enough” actually looks like. This is precisely why use case identification and data quality should not be considered in isolation.
Why is “data quality” in SMEs and family businesses often a systemic issue?
Setting aside the generalised assertion that data quality is critical, let us explore the “why”.
“Poor” data quality in most SMEs and family businesses is neither a failure of individual employees nor a sign of negligence. It is the logical consequence of organically grown structures – and therefore systemic.
Those familiar with European SMEs will recognise that organisations with 50 to 250 employees have typically grown organically, rarely following textbook organisational models but instead developing structures shaped by practical necessity.
Processes were not designed on a drawing board. They were refined over years – typically pragmatic and effective, but seldom documented in detail. Decision-relevant knowledge resides not only in process manuals but also in the minds of experienced employees. IT systems – from the simple spreadsheet without which the business could not function, through to ERP platforms – were introduced to solve specific problems and increase overall effectiveness. A coherent data architecture was a secondary consideration. And over time, data silos and other redundancies have emerged.
This is not a criticism. It is the reality in many organisations. What counts is pragmatism over perfection, workable solutions over ideal structures, execution over academic theory. For all its drawbacks, this approach is precisely what has made many of these businesses successful in the first place.
The consequence is that the level of data quality required for operational AI applications cannot be achieved through an isolated “data clean-up project.” Data does not appear out of thin air. It is the product of processes and of the systems implemented to support those processes.
A white paper published by the Swiss consultancy Initcon [6], synthesising findings from RAND, Gartner, and academic research, identified two cross-industry root causes for AI project failure: first, the failure to determine the organisational need, and second, inadequate data quality.
The failure to determine the organisational need describes, at its core, what is known as the Imagination Gap: organisations implement AI without having systematically clarified which specific problem or process it is intended to solve or improve. [The Imagination Gap – Why Imagination Is the Real AI Bottleneck]
What stands out is that neither cause is purely technical. Both are closely intertwined with organisational questions. [AI in Manufacturing – Different Shop Floor, Similar Challenges?]
Put differently: the state of data quality is not the cause of failed AI projects. It is itself a symptom – of an organisation that has not yet sufficiently understood its processes, knowledge, and use cases.
If data quality is not the starting point – what is?
The temptation to begin with the data is considerable. The logic seems sound: clean up first, then automate. Build the data foundation, then deploy AI.
The difficulty: organisations only know which data quality they actually require once they know which process they intend to support with AI. Data does not exist in a vacuum. It is always tied to a context – a process, a decision, a workflow. Without that context, “tidying up data” becomes a Sisyphean task.
This aligns with what we described in detail in an earlier article on the Imagination Gap [The Imagination Gap – Why Imagination Is the Real AI Bottleneck]. 85 per cent of employees see no value-creating use case for AI in their daily work – not because the tools are lacking, but because the imagination is lacking to identify which processes could meaningfully benefit from AI support [7].
The RAND Corporation found that more than 80 per cent of all AI projects fail, with the primary cause being a fundamental misunderstanding of which problem is actually meant to be solved [8].
This is the Imagination Gap in practice. And it has a direct bearing on data quality: organisations that address the wrong use case prepare the wrong data. Those with no use case at all resort to sorting data and mistake the activity for a clean-up project.
Data quality as an emergent outcome: the maturation cycle
Why treat “data quality” as a problem requiring a one-off solution at the outset of every AI initiative? Why not, instead, recognise good data quality as the emergent outcome of a dynamic maturation process? Not the result of clean-up campaigns, but a by-product that improves incrementally with each iteration – within a cycle that begins in the right place.
A cyclical approach to better data quality
Achieving better data quality through a cyclical approach involves five stages that reinforce one another:
Address the Imagination Gap: Before a single data set is touched, the question must be: where does friction arise in the organisation that no one questions any longer? Which processes consume time without creating value? The Imagination Gap is both the starting point and the barometer for organisational maturity.
Start with a use case: From a sharpened organisational awareness, a concrete use case emerges. In the first iteration, it may not yet be optimally value-creating, and that is perfectly acceptable. An organisation that systematically defines an AI use case for the first time learns more about its processes than any data clean-up project could teach it.
Define and document processes: The chosen use case immediately reveals which sub-processes are undocumented, contradictory, or informal. This is not failure – it is the most valuable insight of the entire cycle. What cannot be clearly described cannot be meaningfully automated. [Is Your Organisation Ready for AI?]
Make knowledge explicit: In many SMEs and family businesses, critical process knowledge exists in the minds of individual employees – as implicit experience that has never been formally recorded. With demographic change, this knowledge will be irretrievably lost in the coming years unless it is transferred into documented process descriptions, SOPs, and decision logic. This step creates the foundation for data quality – not the other way round. [AI Signals Early 2026]
Implement, learn, repeat: Now – and only now – does data quality become tangible and subject to scrutiny. Not as an abstract objective, but as a concrete outcome of the preceding steps. And with each iteration of the cycle, something decisive happens: the Imagination Gap narrows. The organisation recognises new use cases that were invisible in the first iteration. Processes are defined more precisely. Knowledge is documented more systematically. And data quality improves – not because someone launched a data project, but because the organisation has matured.
Why this cycle is never complete
A linear stage model suggests that once all stages have been completed, the problem is solved. The reality is rather different, and involves considerably more effort.
New processes that are not conceivable today will emerge. Existing processes will be discontinued as they prove to lack value. Technology will continue to evolve, opening possibilities that currently lie beyond our imagination.
This means the Imagination Gap will never be fully closed. That is not a deficiency – it is a sign of organisational vitality. Organisations that cease to identify new possibilities stagnate. The objective is not to reduce the Gap to zero, but to build an organisation that becomes progressively better at using that gap productively. With each iteration.
The IDC figures support this approach: organisations with mature data governance – that is, organisations that have completed this cycle multiple times – achieve 24.1 per cent higher revenue and 25.4 per cent cost reduction through AI [5]. This is not coincidental. It is the result of cumulative organisational maturation.
Faster and further: two modes, one critical distinction
In this context, a distinction that we consider fundamental is worth drawing.
“If you want to go fast, go alone. If you want to go far, go together.”
Faster means deploying AI on existing processes to accelerate them. Responding to emails more quickly, producing reports more rapidly, cleaning data more efficiently. This is useful, but limited. AI is reduced to accelerating the status quo.
Further means using AI to question processes fundamentally. Not “How do we do this faster?” but rather “Would we still design this process this way today – and if so, what does the optimal version look like?” [LINK: When AI Intensifies Work Instead of Reducing It]
In our Imagination Gap article, we described an observation by researchers at the University of Leeds: “efficient inefficiency” – organisations that use AI to accelerate tasks that were superfluous from the outset [9]. Data clean-up projects without a clear use case fall into precisely this category: they make something faster that does not take the organisation further. Or, to put it simply: rotation without traction.
The maturation cycle we describe begins with further – with the question of which processes genuinely create value – and applies faster where the context is clear. That is the difference between activity and progress.
And the “together” in the proverb can take on a meaning of its own in the AI context: organisations that understand AI not as an isolated tool but as a team member, integrated into existing workflows, gain precisely the perspective that distinguishes faster from further.
What this means for business leaders
For those who have read this far, a ten-point checklist is probably not what is expected. Indeed, we would have to disappoint on that front.
Instead, we offer three questions that may serve as initial impulses for further discussion:
Is the problem that AI is meant to solve clearly identified? Not in general terms, but specifically and concretely. Which process, which decision, which bottleneck? If the answer remains vague, this is not a data problem – it is an open Imagination Gap.
Could a new team member understand and execute the process based on existing documentation? If the honest answer is “no,” the issue is not data quality – it is a lack of process clarity. And without process clarity, any data clean-up effort is misdirected.
Who in the organisation holds knowledge that exists nowhere in documented form? This question carries an urgency that extends well beyond AI. With demographic change, precisely these knowledge holders will retire in the coming years. Organisations that have not systematically secured this knowledge by then will lose it – along with the foundation for any form of AI-supported process improvement.
The sequence is deliberate. It reflects the entry point into the maturation cycle: first, understand the use case; then, clarify the process; then, secure the knowledge. Data quality does not come before these steps – it emerges from them.
Sources
[1] Gartner: „Lack of AI-Ready Data Puts AI Projects at Risk“ https://www.gartner.com/en/newsroom/press-releases/2025-02-26-lack-of-ai-ready-data-puts-ai-projects-at-risk
[2] Gartner: „Why Half of GenAI Projects Fail“ https://www.gartner.com/en/articles/genai-project-failure
[3] Precisely / Drexel University: „2026 State of Data Integrity and AI Readiness“ Pressemitteilung: https://www.precisely.com/press-release/fourth-annual-study-finds-ai-confidence-outpaces-readiness-as-data-integrity-gaps-persist/ Vollständiger Report (PDF): https://www.lebow.drexel.edu/sites/default/files/2026-01/lebow-precisely-state-data-integrity-ai-readiness-2026.pdf
[4] BARC: “The Data, BI and Analytics Trend Monitor 2026” Zusammenfassung: https://www.strategy.com/software/blog/why-data-quality-is-key-to-ai-success-in-2026
[5] Dataversity: „Trends in Data Management 2026“ https://www.dataversity.net/articles/data-management-trends/
[6] Initcon: White Paper “Why AI Projects Fail“ https://www.initcon.ch/wp-content/uploads/2025/06/Why-AI-Projects-Fail-V1.0.pdf
[7] Section: AI Proficiency Report https://www.sectionai.com/ai/the-ai-proficiency-report
[8] RAND Corporation: “The Root Causes of Failure for Artificial Intelligence Projects” https://www.rand.org/pubs/research_reports/RRA2680-1.html PDF direkt: https://www.rand.org/content/dam/rand/pubs/research_reports/RRA2600/RRA2680-1/RAND_RRA2680-1.pdf
[9] Mills & Spencer: “Efficient Inefficiency” https://www.sciencedirect.com/science/article/pii/S0148296324006325 White Rose Repository: https://eprints.whiterose.ac.uk/220508/
Would you like to strategically implement AI in your daily business operations?
The question is: What does this look like in your company? Do your employees have the competencies they need for this new work reality? Or are AI integration and competency development currently happening side by side – without systematic connection?
In a no-obligation strategy session, we would be happy to introduce you to the NordAGI approach.


